To invoke the structure learning dialog, select Data-Learn New Network... The ensuing dialog allows you to choose variables that will participate in learning, enter background knowledge, and choose one of the available learning algorithms and their parameters.
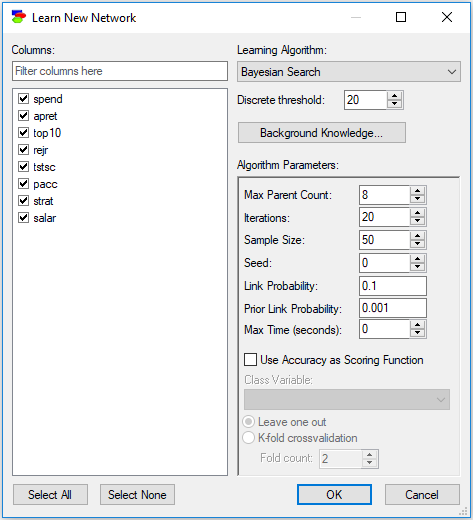
Selecting data columns for structure learning
Check boxes next to variable names on the left-hand side allow us for selecting those variables that will take part in learning. All variables with the check-box checked will be used in structure learning. Given that a practical data set may contains many variables (we have seen in our work with clients as many as 3,500 variables), locating and selecting columns for learning may be daunting. The filter field above the list of data columns serves for selecting columns.
The dialog works similarly to the Find Variable dialog in the Knowledge editor. Typing anything in the filter field causes the dialog to limit the names of data columns to those that match the filter. For example, typing an "a" into the above dialog will lead to the following selection:
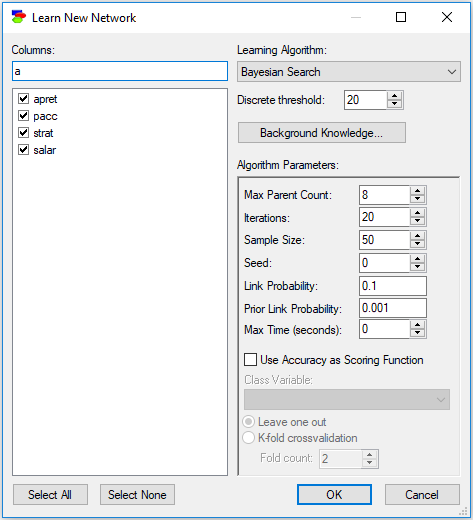
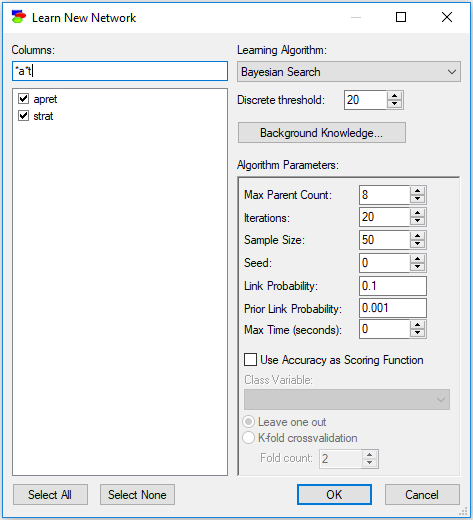
Letter case is ignored, so a lower case letter (e.g., "a") is equivalent to an upper case letter (i.e., "A"). In addition to regular characters, the filter field interprets wildcard characters, such as an asterisk (*) or a question mark (?) similarly to Windows. Typing "*a*t" will select only those column names that have an "a" character and end with a "t":
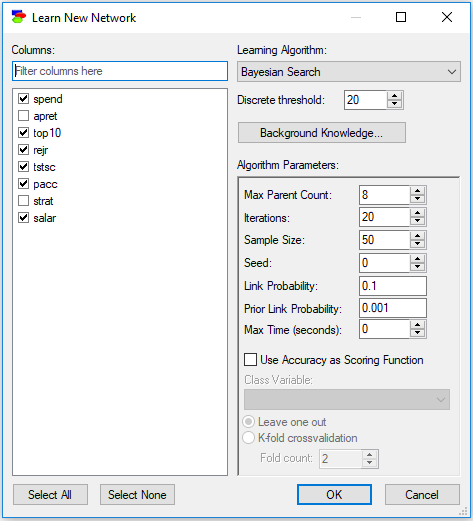
Any of the columns visible in the list can be selected or de-selected. Pressing one of the two buttons, Select All and Select None, will select or de-select columns visible in the column list. The buttons will have no effect on the remaining variables in the data set. If we press Select None button, thus and remove the filter, the effect will be
Finally, the interface allows for copying and pasting the list of selected columns. To that effect, please invoke the context menu on any element of the list
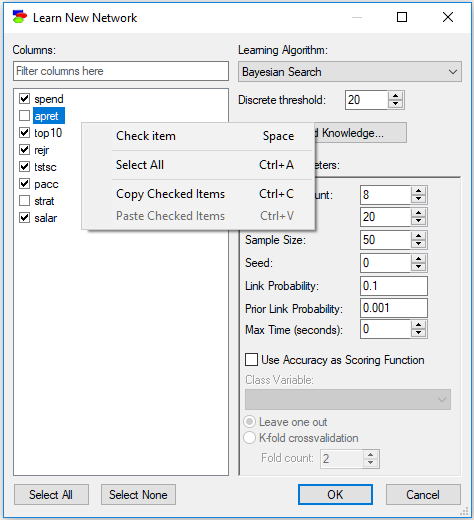
Copy Checked Items will place the list of the selected columns (text format) on the clipboard. The clipboard format is multi-line text containing the names of items in the list. If, at some later stage, we select and copy the text list outside of GeNIe and choose Paste Checked Items, GeNIe will select only the columns on the list. Paste Checked Items command will remove the current check marks, unless the SHIFT key is pressed when command is invoked. This functionality is very convenient in case the list of columns in the data file is large and repetitive column selection process is laborious. The same format is used by Copy Column Names (see Edit Menu for Data Spreadsheets in Cleaning Data), which means that one can select columns directly in the data spreadsheet, use the Copy Column Names command, and then paste the names into the column list to select the same columns in the dialog.
Selecting a structure learning algorithm
The Learning Algorithm pop-up menu allows for selection of the learning algorithm
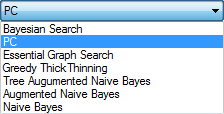
Discrete threshold parameter allows for selecting the minimum number of different states in a variable to be considered continuous. With its default value of 20, any variable that has more than 20 different values will be considered continuous.
Background knowledge
The Background knowledge button invokes the Knowledge Editor dialog, which allows for entering domain knowledge that will aid in the structure learning.
General properties of structure learning algorithms
There are three major obstacles to structure learning that are tested at the beginning of the run of each of the algorithms:
•Each of the structure learning algorithms is capable of structural learning when all variables are categorical. In addition, the PC algorithm allows for learning the structure when all variables are continuous and their joint distribution is multivariate normal. None of the algorithms allows for learning from a mixture of discrete and continuous variables, so if there is a discrete variable in the learning set, it is necessary to discretize all continuous variables. In case the data set contains a mixture of discrete and continuous variables, GeNIe will complain about this and list all discrete and all continuous columns.
•None of the structure learning algorithms (except for the Naive Bayes algorithm, which does not learn the model structure but rather creates it based on strong independence assumption) is capable of learning the structure of a model when there are missing values in the records. In case there are any missing values in the data set, GeNIe will complain about this and list all variables with missing values. Please see also the Missing Values in Cleaning data section.
•None of the structure learning algorithms allows for learning with constant values, i.e., variables (columns in your data) containing the same value across all the records. Constant values are generally useless in learning the structure of a model. The common sense interpretation of this is the following: If a variable x takes the same value in each of the records, then it cannot be a predictor for any other variable. No matter what values the other variables take, x will take the same value anyway. There is, thus, no basis for judgment during the learning process what relationship x has to the remaining variables. In situations when one wants to include x in the model, one could enhance the model afterward by adding x and making a judgment of how x is connected to the rest of the model, including the parameters that describe these connections. In any case, constant variables should not be used in learning and GeNIe will complain if they are included in the learning set.
GeNIe generates a single error report as soon as the algorithm is invoked, so that the user can see in one place what needs to be done to the data for the algorithm to run correctly.
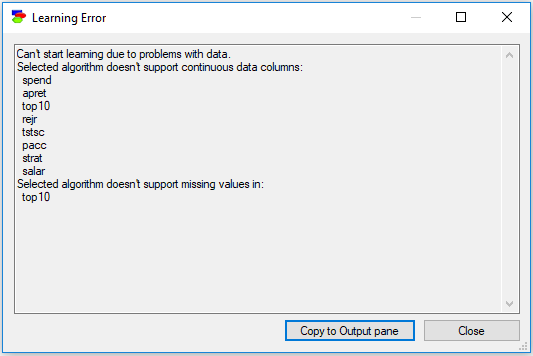
This report can be copied from the dialog and later pasted into an outside program, which is helpful in preparing the data for a new attempt at structure learning.
The remaining parameters are specific to the algorithm selected, although Max Time (seconds) limit is worth mentioning here. Most algorithms return very quickly and most can be interrupted but it is a good idea to set the time limit to some small number of seconds (e.g., 30 seconds) when learning from a new data set. If an algorithm does not return within 30 seconds, there is a good chance that it will need more time than we are willing to wait.
Each of the algorithms produces a graph, which is passed through the simple Parent Ordering layout algorithm for the purpose of readable positioning of nodes on the screen. As the Parent Ordering algorithm may not be able to result in an intuitive layout, the user is encouraged to improve the layout manually.