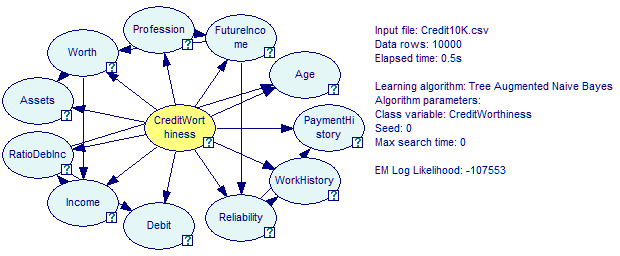
The Tree Augmented Naive Bayes (TAN) structure learning algorithm is a semi-naive structure learning method based on the Bayesian Search approach, described and evaluated in (Friedman et al., 1997). The TAN algorithm starts with a Naive Bayes structure (i.e., one in which the class variable is the only parent of all remaining, feature variables) and adds connections between the feature variables to account for possible dependences among them, conditional on the class variable. The algorithm imposes the limit of only one additional parent of every feature variable (additional to the class variable, which is a parent of every feature variable). Please note that the Naive Bayes structure assumes that the features are independent conditional on the class variable, which may lead to inaccuracies when this assumption is violated. The TAN algorithm is simple and has been found to perform reliably better than Naive Bayes. Here is the Learn New Network dialog for the TAN algorithm:
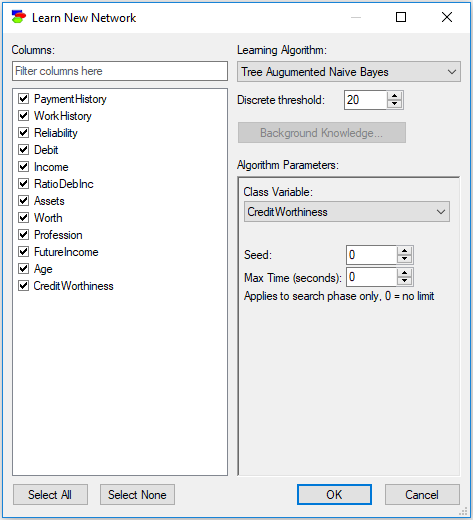
The TAN algorithm has the following parameters:
•Class Variable, which is a pop-up menu forcing the user to select one of the variables as the class variable. This is a crucial choice, as it determines the structure of the graph. Only those variables that are selected in the Columns list appear on the Class Variable pop-up menu.
•Seed (default 0), which is the initial random number seed used in the random number generator. If you want the learning to be reproducible (i.e., you want to obtain the same result every time you run the algorithm), use the same Seed. Seed equal to zero (the default) makes the random number generator really random by starting it with the current value of the processor clock.
•Max Time (seconds) (default 0, which means no time limit) sets a limit on the run time of the search phase of the algorithm. It is a good idea to set a limit for any sizable data set so as to have the algorithm terminates within a reasonable amount of time, although it has to be said that the TAN algorithm is very simple and it is rather unheard of that it does not terminate within a reasonable amount of time.
The algorithm produces an acyclic directed graph with the class variable being the parent of all the other (feature) variables and additional connections between the feature variables. The structure learned is one with the maximum score, similarly to other algorithms based on Bayesian Search. The score is proportional to the probability of the data given the structure, which, assuming that we assign the same prior probability to any structure, is proportional to the probability of the structure given the data.