A feature that is unique to GeNIe among all Bayesian network software that we are aware of is relevance reasoning. Very often in a decision support system, only a small number of variables need updating, either because they are up to date or because they are of no interest to the user. For example, we might want to know the posterior probability distributions over diseases captured in a model but not in the probability distributions over outcomes of unobserved risk factors, symptoms, or test results. When the model used by the system is large, the amount of computation to update all variables may be prohibitive, while potentially unnecessary. Focusing inference on those nodes that we are interested in can save a lot of computation. Reasoning in GeNIe and the underlying SMILE is always preceded by a pre-processing step that explores structural and numerical properties of the model to determine what part of the network is needed to perform computation.
GeNIe keeps track which variables are up to date and which are not and marks them by the Invalid (![]() ) node status icon. It also allows the model builder to designate those variables that are of interest to the user as targets. Target nodes, marked by the Target (
) node status icon. It also allows the model builder to designate those variables that are of interest to the user as targets. Target nodes, marked by the Target (![]() ) node status icon are always guaranteed to be updated by the program during its updating procedure. Other nodes, i.e., nodes that are not designated as targets, may be updated or not, depending on the internals of the algorithm used, but are not guaranteed to be updated. Relevance reasoning is triggered in GeNIe by marking some of the nodes as Targets. If there is at least one target in a model, GeNIe guarantees that all targets will be updated by its reasoning algorithms but does not give any guarantees with respect to any other nodes. When no nodes are designated as targets, GeNIe assumes that all variables in the model are of interest to the user, i.e., all of them are targets.
) node status icon are always guaranteed to be updated by the program during its updating procedure. Other nodes, i.e., nodes that are not designated as targets, may be updated or not, depending on the internals of the algorithm used, but are not guaranteed to be updated. Relevance reasoning is triggered in GeNIe by marking some of the nodes as Targets. If there is at least one target in a model, GeNIe guarantees that all targets will be updated by its reasoning algorithms but does not give any guarantees with respect to any other nodes. When no nodes are designated as targets, GeNIe assumes that all variables in the model are of interest to the user, i.e., all of them are targets.
To set a node to be a target, select it and then choose Set Target from the Node Menu.
Alternatively, right-click on the chosen node and choose Set target from the its pop-up menu:
A target node will display a small target icon (![]() ).
).
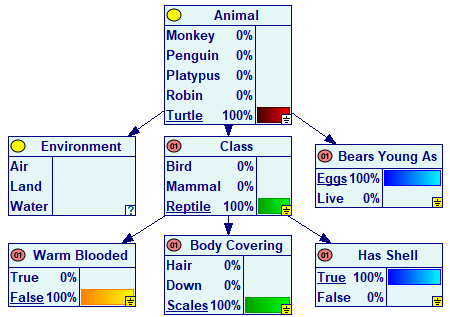
One of the elements of relevance reasoning is propagation of evidence. When a node is observed, it often implies the states of its neighboring nodes with certainty. Consider the following simple network (Animals.xdsl, among the example networks in GeNIe) modeling a simple animal guessing game:
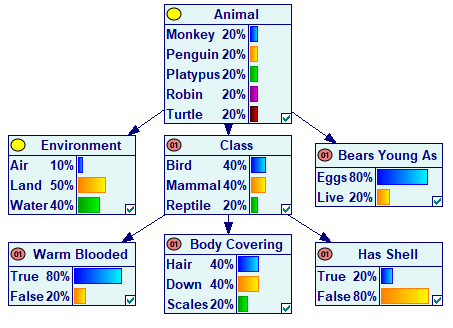
When we establish in the game that the animal has shell, we know for sure that the animal is a reptile, that it is a turtle, lays eggs and has scales for its body covering. These conclusions are just logical implications and can be drawn directly from the underlying probability tables without the need for performing any inference. GeNIe performs the operation of evidence propagation as one of the first steps of relevance reasoning and displays propagated evidence by a modified, yellow observation icon (see the screen shot below).
The foundations of relevance-based algorithms implemented in GeNIe are described in (Druzdzel & Suermondt 1994) and (Lin & Druzdzel 1997, 1998), although GeNIe's implementation goes a few steps further. Relevance algorithms usually lead to substantial savings in computation. We call this pre-processing step collectively relevance reasoning. Relevance reasoning is transparent to the user and the application programmer.
GeNIe has been originally written with teaching graphical models in mind. One of the fundamental concepts on which graphical models are built is conditional independence and relevance (Dawid 1979). In order to demonstrate how nodes are relevant to target variables and to evidence variables, GeNIe allows its user in a mode that does not immediately update nodes after the user has entered an observation or made a change in the model. Those nodes that are marked as not updated after a change has been made are dependent on the change. This mode is also useful in case of an editing session. When editing a network, posterior probabilities may be of little interest. When the model is very large, consisting for example of hundreds of variables, this mode improves the reaction time.