Sometimes the only thing that we might be interested in is the optimal decision at the top level of the influence diagram. Since the policy evaluation algorithm computes the expected utilities of all possible policies, it may be doing unnecessary work. For those cases, SMILE and GeNIe provide a simplified but very fast algorithm proposed by Shachter and Peot (1992). The algorithm instantiates the first decision node to the optimal decision alternative but does not produce the numerical expected utility of this or any other decision option. In order for this algorithm to be run, all informational predecessors of the first decision node have to be instantiated.
Here is an example of the finding the best policy algorithm in action.
Consider the influence diagram from the Building an influence diagram section (included among the example models as VentureID.xdsl).
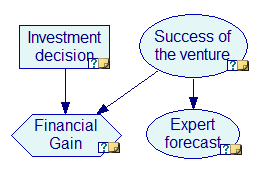
After selecting the Find Best Policy algorithm from the Network Menu and updating the network, only the decision node, Investment decision is updated. The algorithm does not produce the expected utilities but rather indicates which decision option will give the highest expected utility (DoNotInvest in this case).
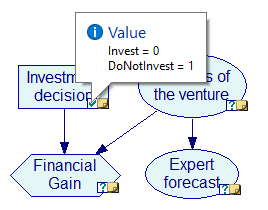
If we had other decision nodes in the model, they would not be updated at this stage. This is because the Find Best Policy algorithm only finds the best policy for the next decision node in the network. To find the best policy for other decision nodes in the network, you first need to set the decision for the first decision node and then update the network again.
If you need to see the expected utilities for the decisions, policy evaluation algorithm is a better choice. Generally, the Find Best Policy algorithm is most suitable for autonomous agents (such as robots or softbots) that just need to know what to do next and are not interested in expected utilities, their relative values, or sensitivities of the optimal policies to various elements of the model.