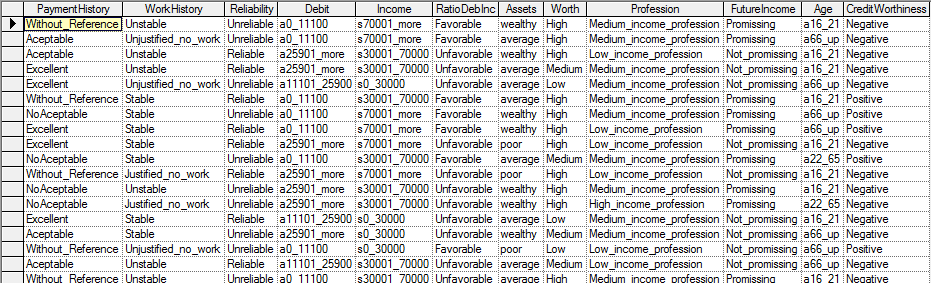
Suppose we have a file Credit10K.csv consisting of 10,000 records of customers collected at a bank. Each of these customers was measured on several variables, Payment History, Work History, Reliability, Debit, Income, Ratio of Debts to Income, Assets, Worth, Profession, Future Income, Age and Credit Worthiness. The file is too large to include in this manual, but it can be downloaded from https://support.bayesfusion.com/docs/Examples/Learning/Credit10K.csv. It is also included in the Examples\Learning directory of GeNIe installation. The first few records of the file (included among the example files with GeNIe distribution) look as follows in GeNIe:
We want to learn the structure of the Bayesian network based on the data. Our program attempts to load the data file from disk, and prints the number of data set variables and records if loading was successful. For clarity, we omit the exception handling in the code snippets here. The tutorial programs include the exception handlers for each learning call.
Java:
DataSet ds = new DataSet();
ds.readFile("Credit10k.csv");
System.out.println(String.format(
"Dataset has %d variables (columns) and %d records (rows)",
ds.getVariableCount(), ds.getRecordCount()));
Python:
ds = pysmile.learning.DataSet()
ds.read_file("Credit10k.csv")
print(f"Dataset has {ds.get_variable_count()} variables (columns)
and {ds.get_record_count()} records (rows)")
C#:
DataSet ds = new DataSet();
ds.ReadFile("Credit10k.csv");
Console.WriteLine(String.Format(
"Dataset has {0} variables (columns) and {1} records (rows)",
ds.VariableCount, ds.RecordCount));
The most general structure learning algorithm is Bayesian Search. It is a hill climbing procedure with random restarts, guided by log-likelihood scoring heuristic. Its search space is hyper-exponential, so for best results the algorithm can be fine-tuned with multiple with multiple options (details are available in the SMILE manual's Reference section). We set the number of iterations (random restarts) to 50, and fix the random number seed to ensure reproducible results. The learn method requires an input data set. The learning algorithm will perform 50 iterations, each starting with randomized structure, and compute a log-likelihood score for at the end of each iteration. The best structure will be copied into the output network, and parameter learning will be run internally. The output network will therefore be ready to use.
Java:
BayesianSearch bayesSearch = new BayesianSearch();
bayesSearch.setIterationCount(50);
bayesSearch.setRandSeed(9876543);
Network net1 = bayesSearch.learn(ds);
Python:
bayes_search = pysmile.learning.BayesianSearch()
bayes_search.set_iteration_count(50)
bayes_search.set_rand_seed(9876543)
net1 = bayes_search.learn(ds)
C#:
BayesianSearch bayesSearch = new BayesianSearch();
bayesSearch.IterationCount = 50;
bayesSearch.RandSeed = 9876543;
Network net1 = bayesSearch.Learn(ds);
The output network looks like this in GeNIe:
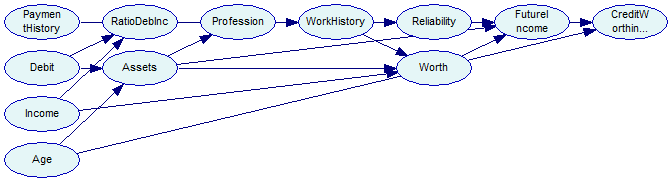
Please note that the nodes in the network learned in SMILE occupy the same screen position. The image below shows the network after the parent ordering layout has been applied. We plan to include simple layout as the last step of the learning in the upcoming release of SMILE.
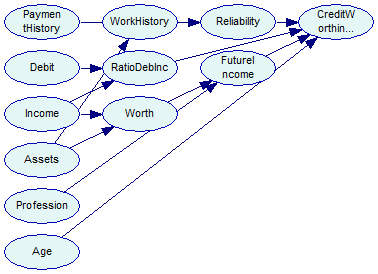
The network is saved for reference in the tutorial9-bs1.xdsl file. We can obtain a different structure by changing the seed for the random number generator and calling learn again. The selected seed value is 3456789, and the output looks like this:
The tutorial saves this network to tutorial9-bs2.xdsl proceeds to third attempt at Bayesian Search, this time with background knowledge. We want to forbid the arc between Age and CreditWorthiness, and force an arc between Age and Profession. When specifying the background knowledge, we refer to the data set variables as their indices, so we need to convert the textual identifiers to indices first.
Java:
int idxAge = ds.findVariable("Age");
int idxProfession = ds.findVariable("Profession");
int idxCreditWorthiness = ds.findVariable("CreditWorthiness");
BkKnowledge backgroundKnowledge = new BkKnowledge();
backgroundKnowledge.matchData(ds);
backgroundKnowledge.addForbiddenArc(idxAge, idxCreditWorthiness);
backgroundKnowledge.addForcedArc(idxAge, idxProfession);
bayesSearch.setBkKnowledge(backgroundKnowledge);
Network net3 = bayesSearch.Learn(ds);
Python:
idx_age = ds.find_variable("Age")
idx_profession = ds.find_variable("Profession")
idx_credit_worthiness = ds.find_variable("CreditWorthiness")
background_knowledge = pysmile.learning.BkKnowledge()
background_knowledge.match_data(ds)
background_knowledge.add_forbidden_arc(idx_age, idx_credit_worthiness)
background_knowledge.add_forced_arc(idx_age, idx_profession)
bayes_search.set_bk_knowledge(background_knowledge)
net3 = bayes_search.learn(ds)
C#:
int idxAge = ds.FindVariable("Age");
int idxProfession = ds.FindVariable("Profession");
int idxCreditWorthiness = ds.FindVariable("CreditWorthiness");
BkKnowledge backgroundKnowledge = new BkKnowledge();
backgroundKnowledge.MatchData(ds);
backgroundKnowledge.AddForbiddenArc(idxAge, idxCreditWorthiness);
backgroundKnowledge.AddForcedArc(idxAge, idxProfession);
bayesSearch.BkKnowledge = backgroundKnowledge;
Network net3 = bayesSearch.Learn(ds);
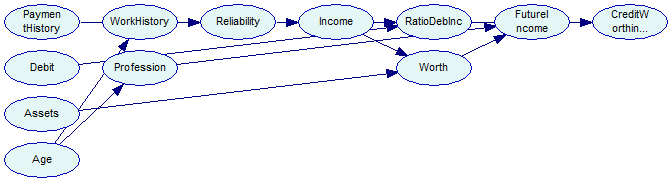
The output network now looks as follows - please note the absence of an arc from Age to CreditWorthiness and the forced arc between Age and Profession. This network is saved to tutorial9-bs3.xdsl.
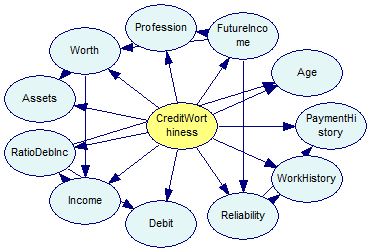
We now change our learning algorithm to Tree Augmented Naive Bayes (TAN). The TAN algorithm starts with a Naive Bayes structure (i.e., one in which the class variable is the only parent of all remaining, feature variables) and adds connections between the feature variables to account for possible dependence between them, conditional on the class variable. The algorithm imposes the limit of only one additional parent of every feature variable (additional to the class variable, which is a parent of every feature variable). We need to specify the class variable with its textual identifier. In this example CreditWorthiness is the class variable.
Java:
Network net4;
TAN tan = new TAN();
tan.setRandSeed(777999);
tan.setClassVariableId("CreditWorthiness");
net4 = tan.learn(ds);
Python:
tan = pysmile.learning.TAN()
tan.set_rand_seed(777999)
tan.set_class_variable_id("CreditWorthiness")
net4 = tan.learn(ds)
C#:
Network net4;
TAN tan = new TAN();
tan.RandSeed = 777999;
tan.ClassVariableId = "CreditWorthiness";
net4 = tan.Learn(ds);
The program saves the network for reference in tutorial9-tan.xdsl file. The network looks as follows (the class node has yellow background):
Our final structure learning algorithm will be PC, which uses independences observed in data (established by means of classical independence tests) to infer the structure that has generated them. The output of the PC algorithm is a pattern, which is an adjacency matrix, and does not necessarily represent a directed acyclic graph (DAG). The pattern can be converted to network with the makeNetwork method, which enforces the DAG criterion on the pattern, and copies the variables and edges to the network.
Java:
PC pc = new PC();
Pattern pattern = pc.learn(ds);
Network net5 = pattern.makeNetwork(ds);
Python:
pc = pysmile.learning.PC()
pattern = pc.learn(ds)
net5 = pattern.make_network(ds)
C#:
PC pc = new PC();
Pattern pattern = pc.Learn(ds);
Network net5 = pattern.MakeNetwork(ds);
At this point our output network has nodes with outcomes based on the labels in the data set, but the probability distributions in node definitions are uniform over outcomes. To complete the learning process, we need to manually call a parameter learning procedure implemented in the EM class.
Java:
EM em = new EM();
DataMatch[] matching = ds.matchNetwork(net5);
em.setUniformizeParameters(false);
em.setRandomizeParameters(false);
em.setEqSampleSize(0);
em.learn(ds, net5, matching);
Python:
em = pysmile.learning.EM()
matching = ds.match_network(net5)
em.set_uniformize_parameters(False)
em.set_randomize_parameters(False)
em.set_eq_sample_size(0)
em.learn(ds, net5, matching)
C#:
EM em = new EM();
DataMatch[] matching = ds.MatchNetwork(net5);
em.UniformizeParameters = false;
em.RandomizeParameters = false;
em.EqSampleSize = 0;
em.Learn(ds, net5, matching);
Note the matchNetwork call, which populates the matching variable using identifiers of data set variables and network nodes. This information is subsequently used by EM.learn to associate data set variables with network node. The output network looks like as follows:
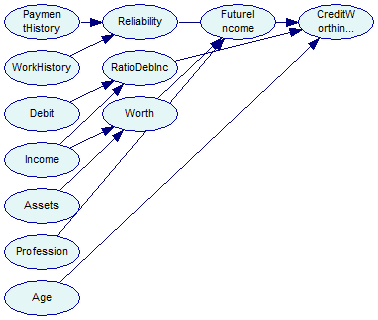
The network is saved for reference in the tutorial9-pc-em.xdsl file and Tutorial 9 finishes.